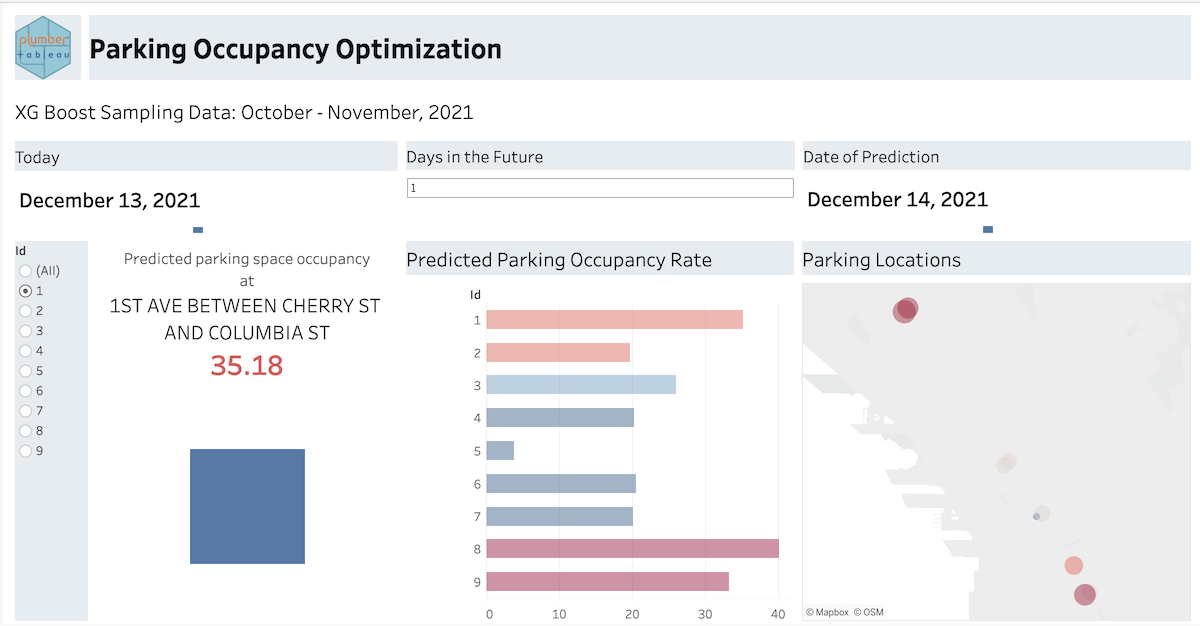
Integrating dynamic R and Python models in Tableau using plumbertableau
The plumbertableau and fastapitableau packages allow you to integrate dynamic R and Python models in Tableau, enhancing your organization’s preferred dashboard tool.
2021-12-20