Model Monitoring with R Markdown, pins, and RStudio Connect
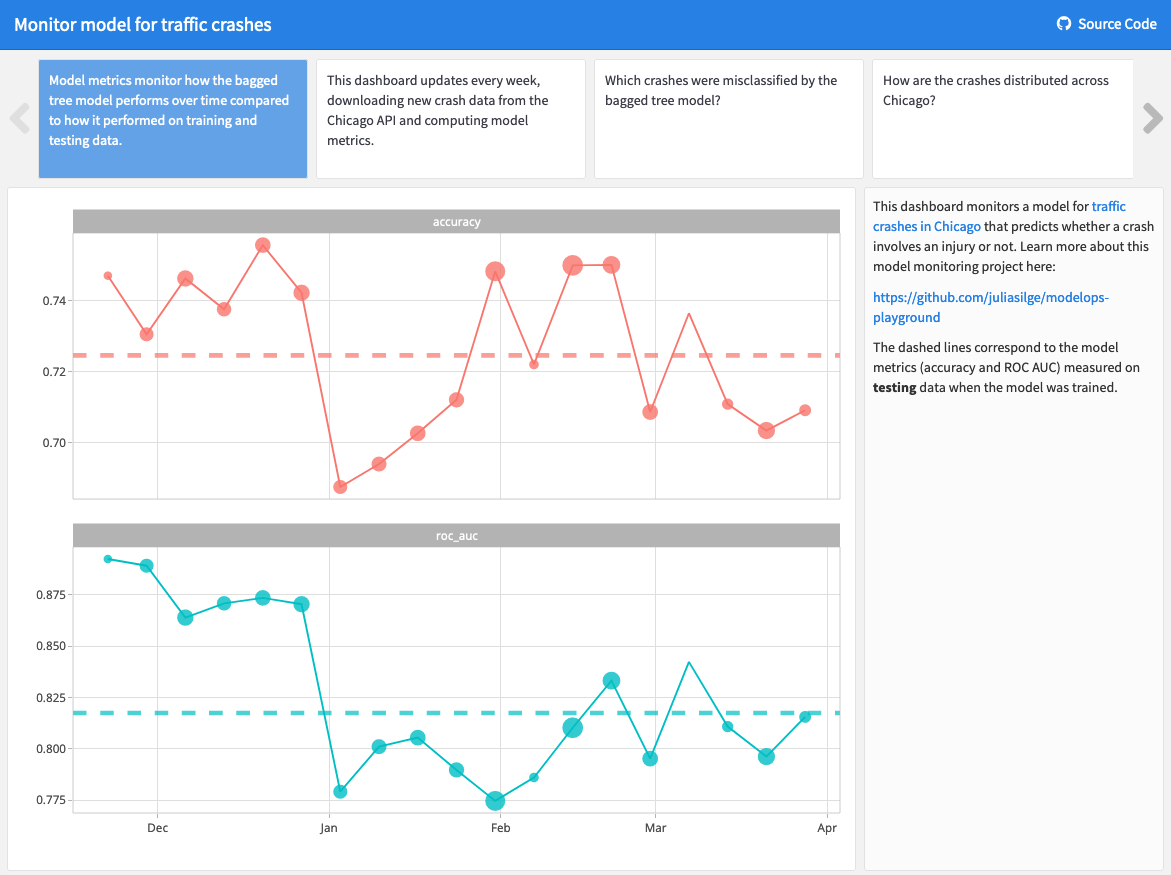
Model monitoring is a key component of ModelOps, and the R ecosystem offers flexible, code-first solutions that meet the model monitoring needs of data science practitioners.
2021-04-08