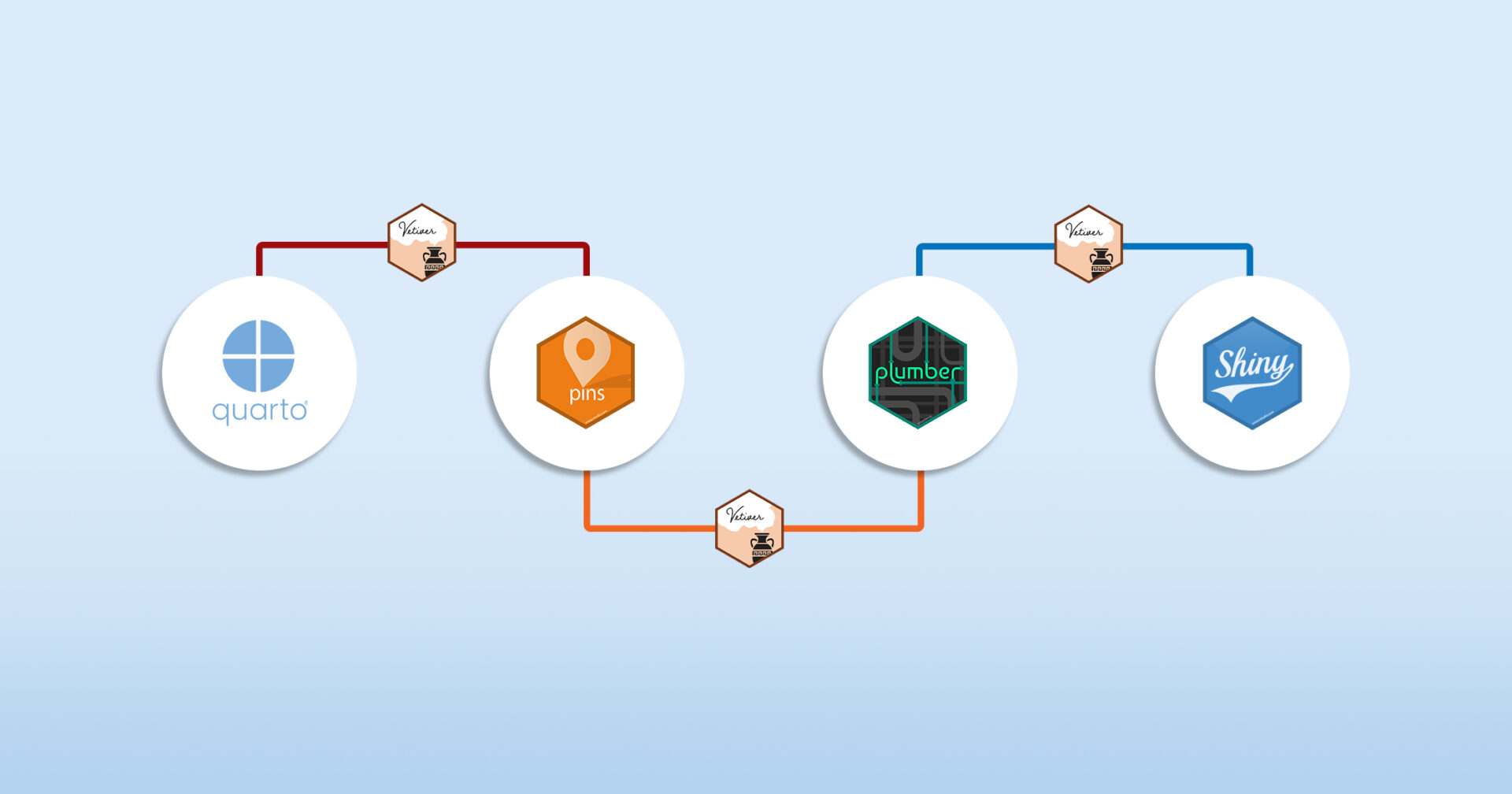
Update Your Machine Learning Pipeline With vetiver and Quarto
With the vetiver package, data scientists have a streamlined, consistent way to maintain machine learning pipelines. We recently updated our Bike Share prediction application using vetiver and Quarto.
2022-09-13